C++的json库特别多。不过总有人追求完美,最近在看jsonxx这个开源的工程。先看下输写代码。
// 最简单的方式创建一个json对象
json obj = {
{ "null", nullptr },
{ "number", 1 },
{ "float", 1.3 },
{ "boolean", false },
{ "string", "中文测试" },
{ "array", { 1, 2, true, 1.4 } },
{ "object", { "key", "value" } }
};是不是看起来和js,php啥的很像
有没有觉得单看这段代码都有种js内味了(误)。但是没错,上面这段代码是C++ !
如果这引起了你的些许兴趣,那就说明这个轮子成功了。
项目地址:https://github.com/Nomango/jsonxx
故事在前
造轮子的初衷是在两年前,我记得那天空中都是圆圆的轮状云,突然想给自己的游戏做一个json格式的配置文件。当我百度一下C++ json库时,被一张图震惊了
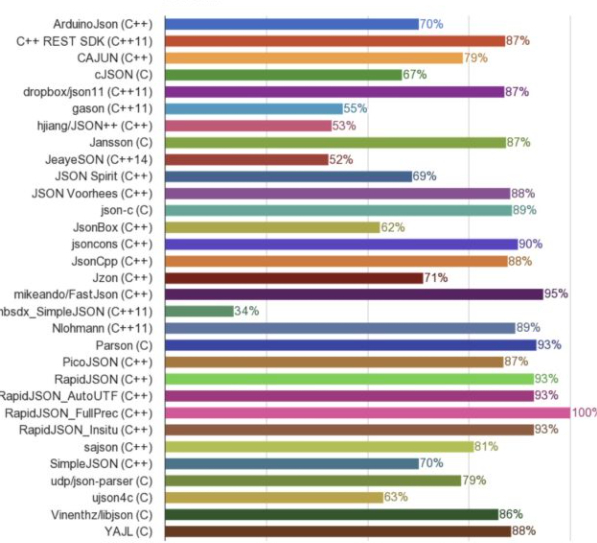 当然震惊我的不是这些库的性能,而是竟然足足有28个比较火的库在互相对比。。还有哪个语言可以做到让这么多人乐此不疲的为了一个小功能写那些重复的逻辑和代码呢?
当然震惊我的不是这些库的性能,而是竟然足足有28个比较火的库在互相对比。。还有哪个语言可以做到让这么多人乐此不疲的为了一个小功能写那些重复的逻辑和代码呢?
将 JSON 对象进行显式或隐式转换
// 显示转换
auto b = j["boolean"].as_boolean(); // bool
auto i = j["number"].as_integer(); // int32_t
auto f = j["float"].as_float(); // float
const auto& arr = j["array"].as_array(); // arr 实际是 std::vector<json> 类型
const auto& obj = j["user"].as_object(); // obj 实际是 std::map<std::string, json> 类型
// 隐式转换
bool b = j["boolean"];
int i = j["number"]; // int32_t 自动转换为 int
double d = j["float"]; // float 自动转换成 double
std::vector<json> arr = j["array"];
std::map<std::string, json> obj = j["user"];
JSON 解析
// 解析字符串
json j = json::parse("{ \"happy\": true, \"pi\": 3.141 }");
// 从文件读取 JSON
std::ifstream ifs("sample.json");
json j;
ifs >> j;
// 从标准输入流读取 JSON
json j;
std::cin >> j;JSON 序列化
// 序列化为字符串
std::string json_str = j.dump();
// 美化输出,使用 4 个空格对输出进行格式化
std::string pretty_str = j.dump(4, ' ');
// 将 JSON 内容输出到文件
std::ofstream ofs("output.json");
ofs << j << std::endl;
// 将 JSON 内容输出到文件,并美化
std::ofstream ofs("pretty.json");
ofs << std::setw(4) << j << std::endl;
// 将 JSON 内容输出到标准输出流
json j;
std::cout << j; // 可以使用 std::setw(4) 对输出内容美化在很简便书写的情况下,笔者发现有2处不足之处。首先,待解析的json字符串如果包含中文,会出错。
json j = json::parse("{\"name\":\"中文\"}");错误 return token_type::parse_error;
解决方法,大概在json_parser.hpp 409行:
//可见utf-8中文 范围未知,暂时都当作字符存进来 3字节

然后就可以解决了。
另外一个问题,如果返回的是unicode编码中文,如\u4e2d,在代码解析的时候,
string_buffer.push_back(char_traits::to_char_type(byte));
byte是utf编码值,20013,明显一个字节存不下,要把wchar转成2个字节的char数组
char* lpStr = (char*)_alloca(2);
WideCharToMultiByte(::GetACP(), 0, (LPCWCH)&byte, -1, lpStr, 2, NULL, NULL);
string_buffer.push_back(char_traits::to_char_type(*lpStr++));
string_buffer.push_back(char_traits::to_char_type(*lpStr));
以上代码会改变2个字节的gbk字符串集,下面方法不会改变,保持原样
if (byte < 0x80) {
string_buffer.push_back(char_traits::to_char_type(byte));
}
else if (byte < 0x800) {
string_buffer.push_back(char_traits::to_char_type(0xc0 | (byte >> 6)));
string_buffer.push_back(char_traits::to_char_type(0x80 | (byte & 0x3f)));
}
else
{
string_buffer.push_back(char_traits::to_char_type(0xe0 | (byte >> 12)));
string_buffer.push_back(char_traits::to_char_type(0x80 | ((byte >> 6) & 0x3f)));
string_buffer.push_back(char_traits::to_char_type(0x80 | (byte & 0x3f)));
}代码差不多在365行左右。
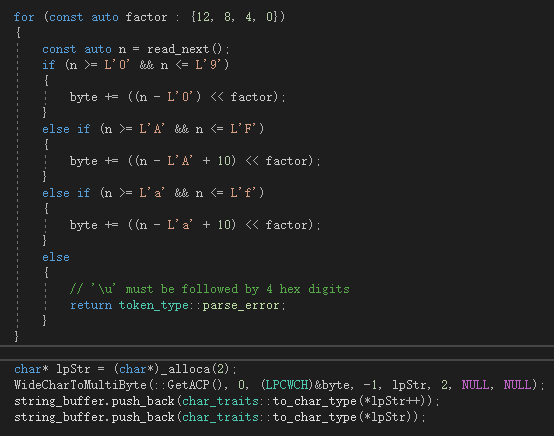 就可以完美解决解析unicode中文了。
就可以完美解决解析unicode中文了。
本文链接:https://it72.com/12672.htm