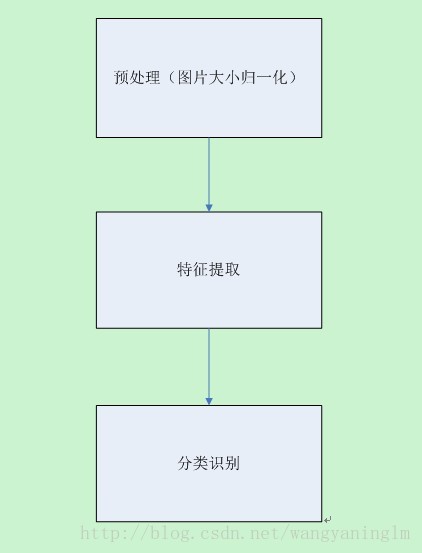
本程序主要参照论文,《基于OpenCV的脱机手写字符识别技术》实现了,对于手写阿拉伯数字的识别工作。识别工作分为三大步骤:预处理,特征提取,分类识别。预处理过程主要找到图像的ROI部分子图像并进行大小的归一化处理,特征提取将图像转化为特征向量,分类识别采用k-近邻分类方法进行分类处理,最后根据分类结果完成识别工作。
程序采用Microsoft Visual Studio 2010与OpenCV2.4.4在Windows 7-64位旗舰版系统下开发完成。并在Windows xp-32位系统下测试可用。
主流程图:
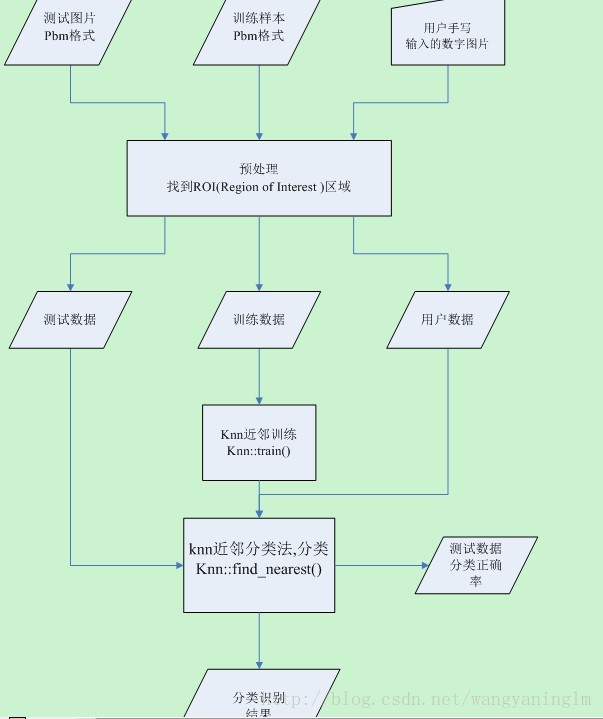
细化流程图:
1. 预处理
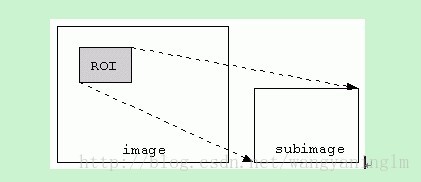
预处理的过程就是找到图像的ROI区域的过程,如下图所示:
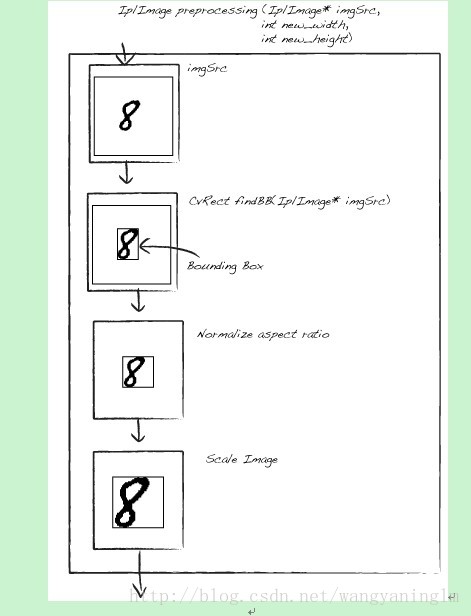
首先找到数字的边界框,然后大小归一化数字图片,主要流程如下图所示:
2. 特征提取
在拿到ROI图像减少了信息量之后,就可以直接用图片作为向量矩阵作为输入:
3. 分类识别
识别方法采用knn近邻分类法。这个算法首先贮藏所有的训练样本,然后通过分析(包括选举,计算加权和等方式)一个新样本周围K个最近邻以给出该样本的相应值。这种方法有时候被称作“基于样本的学习”,即为了预测,我们对于给定的输入搜索最近的已知其相应的特征向量。
K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 KNN方法虽然从原理上也依赖于极限定理,但在类别决策时,只与极少量的相邻样本有关。由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合。
识别工作主要有以下几个步骤:
1. 初始化机器学习算法,及其训练
knn=new CvKNearest( trainData, trainClasses, 0, false, K );
因为trainData, trainClasses数据已得到。训练在CvKNearest算法初始化中已经完成
2. 识别
获取识别测试的数据,testData
result=knn->find_nearest(testData,K,0,0,nearest,0);
result为返回的识别的结果
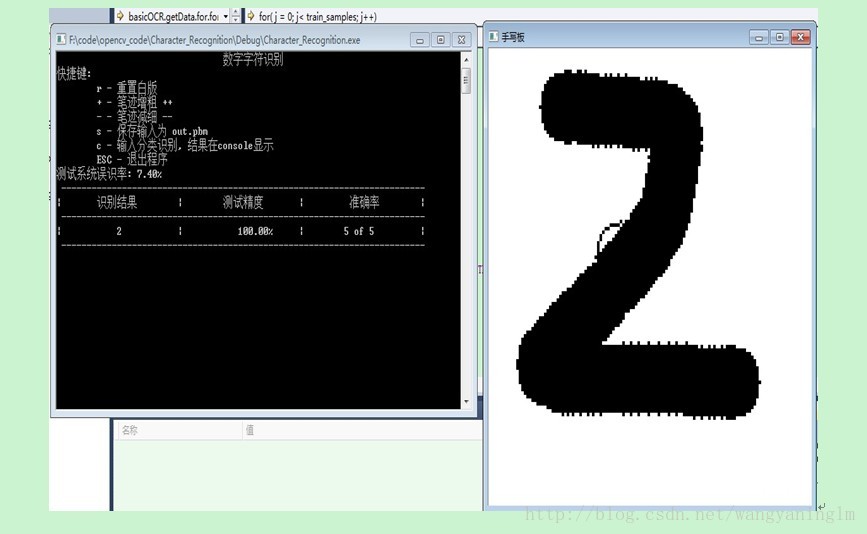
4. 实验结果
在knn参数k=5,子图像向量大小选取128*128像素,训练样本50副图片,测试样本50副图片,系统误识率为7.4%。对于用户手写阿拉伯数字2的识别结果为2,识别比较准确。
5. 未来的工作
本程序主要参照网上的一些实例完成了部署跟实验工作,虽然仅仅完成了手写阿拉伯数字的识别工作,但是字符识别的一些原理工作都是相同的,未来能够从一下几个方面进行提高:
1. 提高程序的识别准确率,从一些文献实现的结果来看,简单的模型结合大量的训练样本,往往效果比复杂的模型结合少量训练样本实现的效果好。
2. 扩展程序的功能,从实现简单的字符到最终实现识别手写汉字等。
3. 提高识别速度,改进算法为并行算法,实现如联机在线识别等。
程序采用Microsoft Visual Studio 2010与OpenCV2.4.4在Windows 7-64位旗舰版系统下开发完成。并在Windows xp-32位系统下测试可用。
主流程图:
细化流程图:
1. 预处理
预处理的过程就是找到图像的ROI区域的过程,如下图所示:
首先找到数字的边界框,然后大小归一化数字图片,主要流程如下图所示:
IplImagepreprocessing(IplImage*imgSrc,intnew_width,intnew_height)
{
IplImage* result;
IplImage* scaledResult;
CvMat data;
CvMat dataA;
CvRectbb;//bounding box
CvRectbba;//boundinb box maintain aspect ratio
//Find bounding box找到边界框
bb=findBB(imgSrc);
cvGetSubRect(imgSrc, &data,cvRect(bb.x,bb.y,bb.width,bb.height));
int size=(bb.width>bb.height)?bb.width:bb.height;
result=cvCreateImage( cvSize( size, size ), 8, 1 );
cvSet(result,CV_RGB(255,255,255),NULL);
//将图像放中间,大小归一化
int x=(int)floor((float)(size-bb.width)/2.0f);
int y=(int)floor((float)(size-bb.height)/2.0f);
cvGetSubRect(result, &dataA,cvRect(x,y,bb.width,bb.height));
cvCopy(&data, &dataA,NULL);
//Scale result
scaledResult=cvCreateImage( cvSize( new_width, new_height ), 8, 1 );
cvResize(result, scaledResult, CV_INTER_NN);
//Return processed data
return *scaledResult;//直接返回处理后的图片
}2. 特征提取
在拿到ROI图像减少了信息量之后,就可以直接用图片作为向量矩阵作为输入:
void basicOCR::getData()
{
IplImage* src_image;
IplImage prs_image;
CvMat row,data;
char file[255];
int i,j;
for(i =0; i<classes;i++)//总共10个数字
{
for(j = 0; j<train_samples;j++)//每个数字50个样本
{
//加载所有的样本pbm格式图像作为训练
if(j<10)
sprintf(file,"%s%d/%d0%d.pbm",file_path,i,i , j);
else
sprintf(file,"%s%d/%d%d.pbm",file_path,i,i , j);
src_image =cvLoadImage(file,0);
if(!src_image)
{
printf("Error: Cant load image %s\n",file);
//exit(-1);
}
//process file
prs_image =preprocessing(src_image,size,size);
//生成训练矩阵,每个图像作为一个向量
cvGetRow(trainClasses, &row,i*train_samples +j);
cvSet(&row,cvRealScalar(i));
//Set data
cvGetRow(trainData, &row,i*train_samples +j);
IplImage*img = cvCreateImage(cvSize( size, size ),
IPL_DEPTH_32F, 1 );
//转换换 8 bits image to 32位浮点数图片取值区间为[0,1]
//scale = 0.0039215 = 1/255;
cvConvertScale(&prs_image,img, 0.0039215, 0);
cvGetSubRect(img, &data,cvRect(0,0,size,size));
CvMatrow_header, *row1;
//convert data matrix sizexsize to vecor
row1 =cvReshape( &data, &row_header, 0, 1 );
cvCopy(row1, &row,NULL);
}
}
}3. 分类识别
识别方法采用knn近邻分类法。这个算法首先贮藏所有的训练样本,然后通过分析(包括选举,计算加权和等方式)一个新样本周围K个最近邻以给出该样本的相应值。这种方法有时候被称作“基于样本的学习”,即为了预测,我们对于给定的输入搜索最近的已知其相应的特征向量。
K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 KNN方法虽然从原理上也依赖于极限定理,但在类别决策时,只与极少量的相邻样本有关。由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合。
识别工作主要有以下几个步骤:
1. 初始化机器学习算法,及其训练
knn=new CvKNearest( trainData, trainClasses, 0, false, K );
因为trainData, trainClasses数据已得到。训练在CvKNearest算法初始化中已经完成
2. 识别
获取识别测试的数据,testData
result=knn->find_nearest(testData,K,0,0,nearest,0);
result为返回的识别的结果
4. 实验结果
在knn参数k=5,子图像向量大小选取128*128像素,训练样本50副图片,测试样本50副图片,系统误识率为7.4%。对于用户手写阿拉伯数字2的识别结果为2,识别比较准确。
5. 未来的工作
本程序主要参照网上的一些实例完成了部署跟实验工作,虽然仅仅完成了手写阿拉伯数字的识别工作,但是字符识别的一些原理工作都是相同的,未来能够从一下几个方面进行提高:
1. 提高程序的识别准确率,从一些文献实现的结果来看,简单的模型结合大量的训练样本,往往效果比复杂的模型结合少量训练样本实现的效果好。
2. 扩展程序的功能,从实现简单的字符到最终实现识别手写汉字等。
3. 提高识别速度,改进算法为并行算法,实现如联机在线识别等。
收藏的用户(0) X
正在加载信息~
推荐阅读
最新回复 (0)
站点信息
- 文章2324
- 用户1338
- 访客12473602
每日一句
You are stronger than you imagine.
你比自己想象的更强大。
你比自己想象的更强大。