看完了介绍,写的相当不错。意简言赅。
K-means介绍K-means算法是聚类分析中使用最广泛的算法之一。它把n个对象根据他们的属性分为k个聚类以便使得所获得的聚类满足:同一聚类中的对象相似度较高;而不同聚类中的对象相似度较小。其聚类过程可以用下图表示:
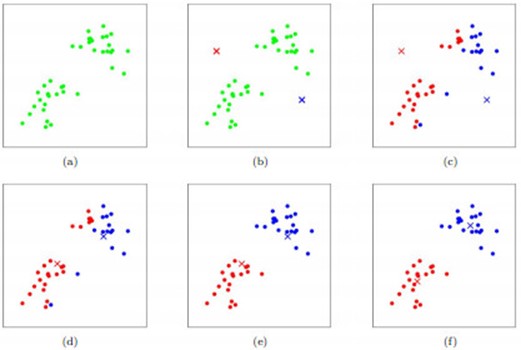
如图所示,数据样本用圆点表示,每个簇的中心点用叉叉表示。(a)刚开始时是原始数据、杂乱无章,没有label,看起来都一样,都是绿色的。(b)假设数据集可以分为两类,令K=2,随机在坐标上选两个点,作为两类的中心点。(c-f)演示了聚类的两种迭代。先划分,把每个数据样本划分到最近的中心点那一簇;划分完后,更新每个簇的中心,即把该簇的所有数据点的坐标加起来去平均值。这样不断进行”划分—更新—划分—更新”,直到每个簇的中心不在移动为止。
K-means算法的缺陷
聚类中心的个数K需要事先给定,但在实际中这个K值得选定是非常难以估计的,很多时候,事先并不知道给定的数据集应该分成多少个类别才最合适
K-means需要人为地确定初始聚类中心,不同的初始聚类中心可能导致完全不同的聚类结果
针对上述第2个缺陷。可以使用K-means++算法来解决K-means++算法k-means++算法选择初始seeds的基本思想就是:初始的聚类中心之间的相互距离要尽可能的远。 1、从输入的数据点集合中随机选择一个点作为第一个聚类中心 2、对于数据集中的每一个点x,计算它与最近聚类中心(指已选择的聚类中心)的距离D(x) 3、选择一个新的数据点作为新的聚类中心,选择的原则是:D(x)较大的点,被选取作为聚类中心的概率较大 4、重复2和3直到k个聚类中心被选出来 5、利用这k个初始的聚类中心来运行标准的k-means算法
从上面的算法描述上可以看到,算法的关键是第3步,如何将D(x)反映到点被选择的概率上,一种算法如下:
1、先从我们的数据库随机挑个随机点当“种子点” 2、对于每个点,我们都计算其和最近的一个“种子点”的距离D(x)并保存在一个数组里,然后把这些距离加起来得到Sum(D(x))。 3、然后,再取一个随机值,用权重的方式来取计算下一个“种子点”。这个算法的实现是,先取一个能落在Sum(D(x))中的随机值Random,然后用Random -= D(x),直到其<=0,此时的点就是下一个“种子点”。 4、重复2和3直到k个聚类中心被选出来 5、利用这k个初始的聚类中心来运行标准的k-means算法 K-means++代码:(http://rosettacode.org/wiki/K-means++_clustering)
KNN(K-Nearest Neighbor)介绍 算法思路:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 看下面这幅图:
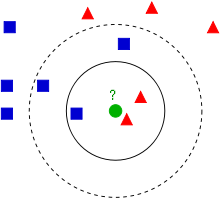
KNN的算法过程是是这样的: 1、从上图中我们可以看到,图中的数据集是良好的数据,即都打好了label,一类是蓝色的正方形,一类是红色的三角形,那个绿色的圆形是我们待分类的数据。 2、如果K=3,那么离绿色点最近的有2个红色三角形和1个蓝色的正方形,这3个点投票,于是绿色的这个待分类点属于红色的三角形 3、如果K=5,那么离绿色点最近的有2个红色三角形和3个蓝色的正方形,这5个点投票,于是绿色的这个待分类点属于蓝色的正方形 4、我们可以看到,KNN本质是基于一种数据统计的方法!其实很多机器学习算法也是基于数据统计的。
KNN与K-Means的区别:1、KNN是分类算法,而Kmeans是聚类算法; 2、KNN属于监督学习,而Kmeans属于非监督学习; 3、KNN的数据集是带有标签的数据,是已经是完全正确的数据,而Kmeans的数据集是没有标签的数据,是杂乱无章的,经过聚类后才变得有点顺序,先无序,后有序。
本文链接:https://www.it72.com/11838.htm